
Introduction
Enterprises today face a growing challenge: AI agents are multiplying rapidly across platforms—procurement bots, clinical assistants, customer service routers, fraud detection systems—but without deliberate orchestration, they create fragmentation, governance gaps, and automation that stalls at the pilot phase. The stakes are high. MIT NANDA's 2025 research found that 95% of generative AI pilot programs fail to deliver measurable P&L impact, with the vast majority either stalling or contributing no business value beyond the proof-of-concept stage.
The root issue is coordination. When individual agents operate in isolation, they can't span cross-system workflows, maintain state across complex processes, or enforce enterprise-grade governance. Organizations end up with disconnected automation islands instead of coherent, scalable systems.
Getting orchestration right separates enterprises that scale AI into measurable business value from those that accumulate expensive, siloed experiments. This guide covers what orchestration actually requires, how to match architecture patterns to your workflows, and what distinguishes implementations that succeed from those that don't.
TLDR
- AI agent orchestration is the connective layer that coordinates multiple specialized agents into coherent, cross-functional enterprise workflows.
- Five orchestration patterns exist (sequential, concurrent, group chat, handoff, Magnetic-One)—picking the wrong one adds latency and cost with no business return.
- Sound evaluation covers six dimensions: cross-domain integration, lifecycle management, governance, AI readiness, scalability, and observability.
- Always verify a single well-tooled agent can't solve the problem before adding multi-agent complexity.
What Is AI Agent Orchestration?
AI agent orchestration is the coordinated management of multiple specialized AI agents—each with distinct capabilities—working together to achieve complex, cross-functional goals in real time.
This differs fundamentally from task-specific automation (discrete, predefined steps without adaptation) and single-model LLM use (isolated prompts without cross-workflow context). Orchestration enables agents to pass context, coordinate handoffs, and adapt execution paths dynamically.
That adaptability makes it suited for workflows where conditions change mid-process, exceptions are frequent, or decisions require interpreting unstructured data.
Core Components of Enterprise AI Agent Orchestration
Three building blocks make orchestration work:
1. Individual agents — Autonomous software entities that observe, reason, and act within a defined domain. One might specialize in document classification, another in compliance validation, a third in risk assessment.
2. The orchestration layer — The logic coordinating agent sequencing, context passing, and task allocation. It determines which agents run when, how results are aggregated, and when human oversight is required.
3. The governance and observability stack Agents execute tasks autonomously. The orchestration layer governs their coordination. The observability stack ensures every action is traceable.
Example: In a healthcare discharge workflow, a clinical summarization agent extracts key treatment data from an EHR, a medication reconciliation agent validates prescriptions against patient allergies and formularies, a care coordination agent schedules follow-up appointments across provider systems, and a billing agent triggers insurance pre-authorization. An orchestration layer maintains patient context throughout, enforces HIPAA audit logging, and routes exceptions to human clinicians when confidence thresholds aren't met.
Why Enterprises Are Prioritizing Agent Orchestration Now
The enterprise agentic AI market was valued at USD $2.58 billion in 2024 and is projected to reach USD $24.50 billion by 2030, growing at a 46.2% CAGR. Three forces are driving this momentum.
- Generative AI breakthroughs lowered implementation barriers: foundation models now provide reasoning, language understanding, and tool-use capabilities that previously required years of custom ML development.
- Cloud hyperscalers shipped enterprise-grade orchestration toolkits between December 2024 and October 2025: AWS Bedrock multi-agent collaboration, Google's Agent Development Kit (ADK), and Microsoft's Agent Framework.
- Distributed enterprise architectures demand interoperability: modern enterprises run on interconnected systems (Workday, Salesforce, ServiceNow, ERP platforms), and single-system agents can't deliver the end-to-end automation ROI enterprises need.
Gartner's 2026 Hype Cycle for Agentic AI reports that only 17% of organizations have deployed AI agents today, but more than 60% expect to deploy within the next two years. The window for early-mover advantage is narrowing fast.

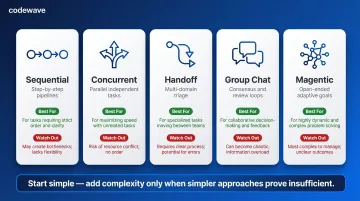
Core Orchestration Patterns Every Enterprise Architect Should Know
The pattern you choose determines latency, cost, governance complexity, and whether your multi-agent system scales beyond pilot. Pattern selection should be driven by how tasks relate to each other — not by how sophisticated the architecture looks.
Sequential Orchestration
Sequential (pipeline) orchestration processes tasks in a predefined linear order, with each agent consuming the output of the previous one.
Use sequential orchestration for step-by-step refinement with clear stage dependencies — for example, document drafting → compliance review → risk assessment, where each stage requires the prior stage's output and cannot run simultaneously.
Avoid it when:
- Stages can be parallelized (latency accumulates across every step)
- Early-stage failures would cascade through the full pipeline
- You cannot afford a single point of failure mid-workflow
Concurrent Orchestration
Concurrent (fan-out/fan-in) orchestration runs multiple agents simultaneously on the same input, then aggregates results afterward.
A financial services firm analyzing a stock, for example, might run fundamental analysis, technical analysis, sentiment analysis, and ESG scoring in parallel — each agent independent, results merged into a unified investment recommendation.
The critical dependency: conflict resolution logic must be defined before deployment. If one agent recommends "buy" and another recommends "sell," the orchestration layer needs predefined rules for reconciling contradictory outputs — otherwise the pattern breaks down at the aggregation step.
Handoff Orchestration
Handoff (routing/triage) orchestration activates one agent at a time, where agents decide when they've reached their capability limits and transfer control to a more appropriate specialist.
This pattern fits multi-domain problems requiring emergent routing — a customer service agent, for instance, triages inquiries and routes to billing, technical support, or account management specialists based on request content.
The primary risk is infinite handoff loops. Without guardrails (maximum handoff count, timeout limits), agents can pass tasks back and forth indefinitely without resolution.
Group Chat Orchestration
Group chat orchestration enables agents to collaborate through a shared conversation thread managed by a chat manager. This pattern suits consensus-building workflows and maker-checker quality loops — one agent drafts a response, another reviews for compliance, a third checks tone and accuracy.
It becomes difficult to control beyond three agents and is prone to infinite conversation loops without explicit termination conditions.
Magentic Orchestration
Magentic orchestration uses a manager agent that dynamically builds and adapts a task ledger for open-ended problems with no predetermined solution path. The manager breaks high-level goals into sub-goals, delegates to specialist agents, evaluates results, and adjusts the plan iteratively.
It carries the most variable cost and slowest convergence of any pattern. Deploy this only after your governance infrastructure is mature enough to handle unpredictable execution paths.
Decision Logic: Start Simple
Start with the simplest approach that reliably meets requirements: a direct model call, then a single agent with tools, then multi-agent orchestration. Each step up adds coordination overhead, latency, and new failure modes — none of which are worth introducing until a simpler approach has proven insufficient.
Microsoft's Azure Architecture Center guidance recommends starting with the lowest level of complexity that reliably meets requirements. Add orchestration only when a single agent cannot handle the workflow scope.
How to Evaluate AI Agent Orchestration for Your Enterprise: 6 Key Factors
Effective evaluation spans both technical architecture and business operations. The platform that fits your organization aligns with your existing workflows, data environment, governance requirements, and team capabilities — not just the one with the most impressive feature list.
Cross-Domain Integration and Extensibility
Enterprise workflows routinely cross system boundaries. An HR onboarding workflow touches Workday, ServiceNow, and Azure AD simultaneously. An orchestration layer that only coordinates within one platform creates gaps and handoff failures at every boundary.
Ask:
- Can a single workflow span network, cloud, security, and application domains?
- Does the platform support pre-built connectors and custom integrations without rewriting core orchestration logic?
- How does the system handle API versioning when integrated tools change?
Track: request-to-fulfillment cycle time, manual touchpoints avoided, and cross-system workflow success rate.
Lifecycle Management and Stateful Orchestration
Tracking service state across its full lifecycle — provisioning, updates, drift detection, rollback, retirement — separates sustainable orchestration from one-off automation. Without stateful tracking, every incident becomes a manual investigation.
Ask:
- Does the platform maintain a state model per service instance?
- Can it detect and remediate configuration drift automatically?
- Are rollbacks and version histories available for audit and recovery?
Track: change-fail rate, drift incidents per month, and audit preparation time.
Governance, Security, and Auditability
Teradata's 2025 survey of 500+ AI executives found that 93% face challenges creating governance and guardrails for AI initiatives. Governance needs to be built into the orchestration layer at the design stage — adding it after deployment is significantly harder and leaves real exposure in the interim.
Ask:
- Are all operations—human, API, and agent-initiated—logged with identity, timestamp, and version?
- Does the platform enforce RBAC, integrate with identity providers, and protect secrets?
- Are AI-initiated actions subject to the same policy enforcement as manual ones?
Critical regulatory context: The EU AI Act's high-risk system requirements take effect August 2, 2026, requiring transparency, auditability, and human oversight for AI systems impacting employment, education, law enforcement, and migration. NIST AI RMF 1.0 provides a four-function governance backbone (Govern, Map, Measure, Manage) that enterprises should map to orchestration-specific risks now.
AI and Agent Readiness
Production agentic workloads have specific demands: reversible actions, traceable decisions, and policy-enforced approval flows. "AI-ready" marketing language rarely tells you whether a platform meets those requirements under real load.
Ask:
- Are agent-driven changes reversible, logged, and traceable?
- Does the platform include an agent mediation layer that routes AI proposals through policy-enforced workflows, validations, and approvals?
- Can agents trigger orchestration mid-workflow (e.g., anomaly detection adjusting a configuration) without bypassing governance?
- Does the platform support hybrid usage—manual, automated, and agentic—so teams can adopt AI incrementally?
Track: agent task completion rate, tool selection accuracy, and escalation rate from agent to human.
Scalability and Reliability
Orchestration that works in pilot breaks in production — this is one of the most consistent failure patterns in enterprise AI deployments. Multi-agent systems multiply model invocations, accumulate context across agents, and introduce distributed failure modes (node failures, message loss, cascading errors) that single-agent prototypes never surface.
Ask:
- Does the platform scale horizontally under high concurrency?
- Are retry, fallback, and circuit-breaker mechanisms built in?
- Is context compaction (summarizing prior agent exchanges to stay within model limits) supported between agents?
Track: orchestration uptime, latency under peak load, and incident recovery time.
Even a highly reliable system creates operational risk if you can't see inside it — which makes observability the final, and often underweighted, factor.
Observability and Evaluation Methodology
Production AI agent systems require continuous, multi-dimensional evaluation. Pre-deployment testing establishes a baseline — it cannot capture how performance shifts under real-world variation.
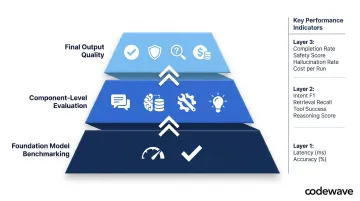
Amazon's three-layer evaluation model from building thousands of agents provides the framework:
| Layer | What It Measures | Key Metrics |
|---|---|---|
| Foundation model benchmarking | Selects appropriate models powering agents | Model-level accuracy, latency impact |
| Component-level evaluation | Assesses individual agent components | Intent detection, memory/context retrieval, tool selection accuracy, tool parameter accuracy, reasoning coherence |
| Final output quality | Assesses end-to-end response and success | Task completion, response relevance, safety/hallucination metrics, cost |
Ask:
- Can workflow failures be traced to exact steps and agent versions?
- Are LLM-as-judge evaluators available for non-deterministic outputs?
- Is human-in-the-loop evaluation supported for high-stakes decisions?
Critical insight: Stanford researchers found GPT-4's math accuracy dropped from 84% to 51% in just three months (March to June 2023) — a 33-percentage-point decline with no model change on the user side. Continuous production monitoring isn't optional; it's how you catch this kind of drift before it affects business outcomes.
Common Implementation Pitfalls (and How to Avoid Them)
Pitfall 1: Over-Engineering the Architecture
Enterprises default to complex multi-agent orchestration when a single agent with well-defined tools would suffice. Each added agent introduces coordination overhead, latency, and a new failure mode.
Map the simplest architecture that reliably meets requirements before layering in agents. Use this hierarchy:
- Direct model call (single prompt/response)
- Single agent with tool access
- Multi-agent orchestration (only if workflow spans multiple domains or exceeds single-agent context limits)
Pitfall 2: Treating Governance as an Afterthought
Teams rush to ship agentic workflows and retrofit audit trails, access controls, and compliance monitoring afterward — by which point production risks are already live.
Define governance requirements before architecture decisions are made. Every design choice should account for:
- RBAC and access controls — who can trigger which agents and with what permissions
- Audit logging and explainability — traceable decision paths for compliance and debugging
- AI guardrails — boundaries that prevent runaway agent behavior in production
Governance shapes the architecture. It cannot be bolted on after the fact.
Pitfall 3: Evaluating Agents as Black Boxes
Measuring only final output quality misses the intermediate failure points that silently degrade multi-agent systems: tool selection errors, context retrieval failures, and intent misclassification. These rarely surface in end-to-end tests — they accumulate quietly until they become production incidents.
Build evaluation across all three layers — model, component, and output — from day one, and pair it with continuous production monitoring and automated anomaly alerts. According to Gartner's 2025 research, organizations performing regular AI system assessments are 3x more likely to achieve high GenAI business value.

How Codewave Can Help You Build the Right Orchestration Architecture
Codewave helps enterprises move from isolated AI experiments to production-grade agent orchestration by aligning architecture decisions with measurable business outcomes. With 400+ businesses served across 15+ industries — including healthcare, fintech, retail, and insurance — the team brings pattern recognition from real deployments, not theoretical frameworks.
Codewave's ImpactIndex™ model ties delivery to verified performance metrics — enterprises pay only for orchestration that hits defined thresholds in production, not estimated value at sign-off.
Key capabilities:
- QuantumAgile™ validates orchestration architecture through rapid simulation before full build, reducing the risk of costly architectural pivots
- ZeroDX™ removes handoff layers so the architects who design the orchestration system are the same practitioners who build it — no strategy-to-execution gaps
- Demonstrated results across AI and data projects: 40% increase in productivity, 25% reduction in costs, and 90% reduction in data errors
- Cross-industry pattern library and governance frameworks that give evaluation teams proven templates and implementation blueprints to work from immediately
Conclusion
The right AI agent orchestration architecture is not the most sophisticated one—it is the one that matches your workflow complexity, data environment, governance requirements, and team's current maturity. Start with the simplest architecture that reliably meets the need.
That simplest architecture will also need to evolve. Agent performance degrades as conditions shift, typically driven by:
- Underlying model updates that alter output behavior
- Data distribution changes that erode accuracy
- New tool integrations that introduce unexpected interactions
Build for those realities from day one. Continuous evaluation, production monitoring, and periodic architecture review are what separate orchestration systems that hold up in production from those that quietly drift off-target.
Frequently Asked Questions
What is the difference between AI agent orchestration and traditional workflow automation?
Traditional workflow automation follows predefined, rule-based logic with fixed decision trees. AI agent orchestration enables dynamic, context-aware coordination where agents reason about what to do next—so it handles workflows where conditions change, exceptions are frequent, or decisions require interpreting unstructured data.
When does an enterprise actually need multi-agent orchestration versus a single AI agent?
Multi-agent orchestration is justified when tasks span multiple domains (e.g., cross-system workflows requiring specialized capabilities per domain), require distinct security boundaries per agent, or are too complex for a single prompt context. Otherwise, a single agent with well-defined tool access is simpler to build, test, and maintain.
What are the most common reasons enterprise AI orchestration implementations fail to scale?
The three primary failure modes are: tool integration failures (poorly defined API schemas causing erroneous agent tool selection), governance gaps (AI-initiated actions bypassing policy controls), and evaluation blind spots (only measuring final output rather than intermediate agent behaviors like intent detection and context retrieval).
How should enterprises handle governance and compliance in AI agent orchestration?
Governance must be embedded in the orchestration layer itself—every agent-initiated action should pass through the same policy enforcement, approval gates, and audit logging as human-initiated changes. Frameworks like the EU AI Act and NIST AI RMF define the compliance baseline; design for them from the start rather than retrofitting later.
What metrics should enterprises track to measure AI agent orchestration ROI?
Track request-to-fulfillment cycle time, manual touchpoints eliminated, change-fail rate, agent task completion rate, escalation rate (agent to human), and audit preparation time. Pair these operational metrics with business outcomes—cost reduction and productivity gains—tied directly to the workflows being orchestrated.
How does AI agent orchestration differ across industries like healthcare, fintech, and retail?
Orchestration patterns and governance requirements vary significantly by industry: healthcare requires strict human-in-the-loop oversight and full auditability for clinical workflows; fintech demands low-latency concurrent orchestration with fraud detection guardrails built in; and retail relies on escalation handoff patterns to manage customer service edge cases. The pattern and governance model must be selected based on the specific workflow context, not a generic template.


