
Introduction
Enterprise AI deployments fail at an alarming rate—Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs, unclear business value, and inadequate risk controls. The problem often starts before you write a single line of code: poor architecture choices compound into expensive rebuilds, unreliable systems, and scaling paths that collapse under production load.
Your agent architecture determines everything: cost structure, latency profiles, debugging complexity, and whether your system executes tasks or spirals into cascading failures.
Choose a multi-agent swarm when a single ReAct loop would suffice, and you'll pay 10x more per request while chasing communication failures between agents. Pick a rigid planning-based pattern for a task requiring dynamic adaptation, and your agent will fail the moment reality diverges from its plan.
Getting the architecture right from the start is the difference between a system that scales and one that gets scrapped. This guide covers the major AI agent design patterns, their trade-offs, and a practical framework for matching the right pattern to your workload complexity, latency tolerance, cost constraints, and governance requirements.
TLDR
- Your agent architecture choice—how a system perceives, remembers, plans, and acts—directly shapes latency, cost, and reliability.
- Single-agent patterns (ReAct, planning-based) handle focused, single-domain tasks with fewer model calls and simpler debugging.
- Multi-agent patterns break complex cross-domain workflows into parallel or sequential steps—but add coordination overhead and cost.
- Iterative patterns (critique loops, human-in-the-loop) add self-correction and compliance checkpoints where quality matters most.
- Start with the simplest architecture that meets requirements, then scale up based on task complexity, latency tolerance, budget, and governance needs.
What Is AI Agent Architecture and Why Does Structure Matter?
AI agent architecture is the structural design that governs how an autonomous system perceives its environment, manages context, plans actions, and executes decisions. Unlike traditional software following predefined logic paths, agents must handle uncertain inputs and shifting goals—making these architectural choices critical to whether a system succeeds or collapses under real-world conditions.
The Five Core Components
Research published in Frontiers of Computer Science (cited 3,410 times) identifies four foundational modules present in all agent architectures, with a fifth—Feedback—essential for any production deployment:
| Component | Function | Example |
|---|---|---|
| Perception | Converts environment signals into structured representations the system can reason about | User queries, API responses, sensor data, document contents |
| Memory | Short-term: active context in the LLM window. Long-term: vector databases or knowledge graphs for cross-session retrieval | Conversation history, retrieved facts, learned behaviors |
| Planning | Decomposes complex objectives into executable subtasks using strategies from Chain-of-Thought to Tree-of-Thoughts | Multi-step research tasks, dynamic replanning mid-execution |
| Action | Translates decisions into real-world outputs — API calls, database queries, generated text, triggered workflows | Changing state in external systems |
| Feedback | Observes action outcomes, compares against goals, and adjusts future behavior for iterative refinement and error recovery | Self-correction loops, retry logic, goal re-evaluation |

The Business Case for Getting Architecture Right
Those five components don't just describe what agents do — they explain why poorly designed ones fail at scale. The Gartner 40% cancellation rate isn't random. It tracks directly to three compounding failure modes:
- Cost overruns: Unorchestrated multi-agent systems can require 10-15 LLM calls per task instead of 2-3. At GPT-4.5 pricing ($2.50/M input tokens, $15.00/M output tokens), a $0.05 task can balloon to $0.75 — multiplied across thousands of daily requests.
- Reliability collapse: Production data from 1,642 execution traces shows failure rates of 41% to 86.7% in unorchestrated systems. Coordination latency grows from 200ms with two agents to over four seconds with eight — each handoff a new failure point.
- Brittle scaling: Agents built for predictable workflows fail when tasks require mid-execution adaptation. ReAct-style dynamic loops, conversely, break down beyond 8-10 tools due to tool selection errors and context degradation.
Single-Agent Design Patterns
Start here. Single-agent systems handle most enterprise tasks requiring multi-step reasoning, external tool access, or adaptation within a single domain. Anthropic explicitly recommends starting with the simplest solution and only increasing complexity when needed.
ReAct (Reason and Act) Pattern
The ReAct pattern (Yao et al., ICLR 2023) alternates between three phases:
- Thought: The agent reasons about the current state, available tools, and next action
- Action: The agent selects a tool or generates a query
- Observation: The agent processes tool output and updates context
This cycle repeats until the task completes or an exit condition triggers.
Trade-offs:
ReAct is transparent (reasoning traces make debugging easier) and adaptable (the agent adjusts mid-task based on observations). However, each loop requires at least one additional LLM call, increasing latency and cost. On HotpotQA question answering, ReAct achieved 35.1% accuracy versus 28.7% for standard baselines using only one-shot prompting. On interactive ALFWorld tasks, ReAct reached 71% success rates compared to 37% for trained baselines.
Best for: Tool-heavy workflows where dynamic adaptation between steps is essential—such as customer service agents routing between knowledge bases, CRM systems, and ticketing APIs based on real-time context.
Planning-Based Agent Pattern
A planner agent generates a complete task plan upfront, then an executor runs each step sequentially. Unlike ReAct's iterative loop, planning typically requires fewer LLM calls: one planning call plus the execution calls themselves. That makes it more cost-efficient for structured, predictable work.
Limitation:
Planning-based agents are brittle when tasks require mid-execution adaptation not anticipated in the original plan. If step three reveals information that invalidates step five, the agent continues executing a flawed plan rather than replanning.
Best for: Predictable, well-scoped tasks with stable requirements. Data processing pipelines that extract, transform, validate, and load structured data through fixed stages are a natural fit.
When to Upgrade Beyond Single-Agent
If your agent manages more than 8–10 tools, performance degrades measurably:
- Tool selection accuracy drops as the LLM evaluates a growing option set per decision
- Latency climbs with each additional tool the model must reason over
- Unexpected tool interactions create compounding edge cases that are hard to debug
When you hit these symptoms, multi-agent decomposition is the logical next step: splitting specialized tool clusters into dedicated sub-agents, each with a focused scope and a cleaner decision surface.
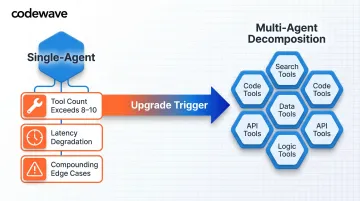
Multi-Agent Design Patterns for Complex Workflows
Multi-agent systems decompose large objectives into specialized sub-tasks assigned to dedicated agents. While this improves scalability and maintainability, it introduces coordination overhead, more model calls, and new failure modes—communication errors, state inconsistency, and cascading failures.
Sequential and Parallel Patterns
Sequential Pattern Agents execute in a predefined linear order where each agent's output becomes the next agent's input. A contract review pipeline might flow: extract key terms → check against company policy → assess legal risk → calculate financial exposure.
The core limitation is rigidity. Failures in early stages propagate downstream, and the pipeline cannot adapt dynamically. Sequential patterns work best for stage-dependent workflows where each phase legitimately requires the previous phase's complete output.
Parallel (Concurrent) Pattern Multiple specialized agents execute independently on the same input simultaneously. A financial risk system might run transaction analysis, credit evaluation, and market exposure checks in parallel, then aggregate results.
This comes at a cost: multiple LLM calls execute concurrently, driving up immediate resource consumption, and result synthesis logic grows complex. Parallel patterns excel when independent analyses are needed simultaneously and no analysis depends on another's output.
Coordinator and Hierarchical Patterns
Coordinator Pattern A central coordinator agent uses an AI model to dynamically analyze requests, decompose them into sub-tasks, and route each to appropriate specialists. Unlike sequential/parallel patterns where routing is predefined, the coordinator decides at runtime based on request characteristics.
This pattern fits structured business processes with varied input types. A customer service agent, for example, routes order inquiries, refund requests, and return authorizations to different specialists based on detected intent.
Hierarchical Task Decomposition Pattern Extends the coordinator pattern across multiple levels. A root agent decomposes a complex goal into sub-tasks, delegates to mid-level agents who further decompose, and worker agents execute at the lowest level.
The trade-off is latency and cost. A three-level hierarchy generates 7+ LLM calls for a single request—root planning, mid-level decompositions, and worker executions all stack up.
Google's ADK documentation recommends this pattern for ambiguous, open-ended problems where tasks exceed a single agent's context window: research projects requiring literature review, data analysis, and synthesis across multiple domains.
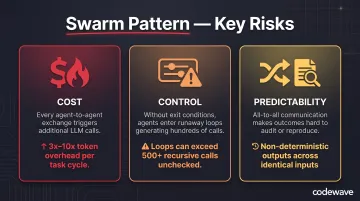
Swarm Pattern
Multiple specialized agents communicate all-to-all, sharing findings, critiquing proposals, and gradually converging on solutions without a central orchestrator. Any agent can hand off to another or return a final response.
Swarms produce well-rounded, multi-perspective solutions for complex, ambiguous problems—product design being a prime example, where market analysis, engineering feasibility, cost modeling, and competitive positioning all need independent evaluation.
The risks, however, are significant:
- Cost: Every agent-to-agent exchange triggers additional LLM calls, making swarms the most resource-intensive pattern
- Control: Without explicit exit conditions (iteration caps or consensus thresholds), agents can enter runaway loops and generate hundreds of calls before converging
- Predictability: All-to-all communication means outcomes are harder to audit and reproduce than in coordinator or sequential patterns
Iterative, Reflection, and Special-Purpose Patterns
Loop and Review-Critique Patterns
The loop pattern is the foundation of this group: an agent repeatedly executes a sequence of sub-agents until an exit condition is met—maximum iterations or a quality threshold.
The review-and-critique (generator-critic) pattern is a specialized loop where a generator agent produces output and a critic agent evaluates it against predefined criteria, returning feedback until the output is approved. Research on Self-Refine demonstrated approximately 20% average improvement across seven tasks, with math reasoning solve rates improving from 22.1% to 59.0%. Most quality gains appear in the first 2-3 iterations before plateauing.
Best for: content creation, code generation, or any workflow requiring a distinct quality gate before delivery.
The iterative refinement pattern takes this further—one or more agents progressively improve output stored in session state across multiple cycles. This suits complex generation tasks like long-form writing or multi-part planning, where single-pass approaches fall short on quality.
One real trade-off to plan for: latency and cost grow proportionally with each cycle. A five-iteration refinement loop costs 5x a single-pass approach.
Human-in-the-Loop Pattern
Where iterative patterns rely on automated feedback, some workflows need a human in that role. At a predefined checkpoint, the agent pauses execution and waits for a human reviewer to approve, correct, or provide input before proceeding.
This pattern is essential for:
- High-stakes decisions—large financial transactions, sensitive document release, compliance validation
- Regulated industries where AI autonomy must be bounded
- EU AI Act Article 14 compliance, which requires high-risk AI systems to enable human override, support awareness of automation bias, and allow the system to be stopped
Architectural complexity is the main cost. Implementation requires:
- Building external interfaces for human interaction
- Persisting state at pause checkpoints so workflows resume without replaying prior steps
- Scoping review gates to sensitive actions rather than full outputs, to reduce friction
How to Choose the Right Architecture Pattern for Your Use Case
Evaluate four dimensions before selecting an architecture:
1. Task Complexity
Is the task focused/single-domain or cross-domain/ambiguous? Single-domain tasks favor single-agent or planning-based patterns. Cross-domain tasks requiring multiple specialized skill sets favor multi-agent decomposition.
2. Latency Tolerance
Can you accept multi-step delays for higher quality, or is real-time response critical? Iterative refinement and hierarchical patterns introduce seconds to minutes of latency. Real-time applications require single-agent or parallel patterns.
3. Cost Budget
How many LLM calls per task is acceptable at your request volume? At 10,000 requests per day, a pattern requiring 10 LLM calls versus three calls costs $4,500 more per month at mid-tier model pricing ($2.50/$15.00 per million tokens).
4. Governance and Compliance
Does the task require audit trails, human oversight, or centralized policy enforcement? Regulated industries need human-in-the-loop checkpoints, while autonomous applications prioritize speed over oversight.
Pattern Selection Summary
| Pattern | Best For | Key Trade-off |
|---|---|---|
| ReAct | Dynamic, single-domain tasks with tool use | Higher latency per task vs. planning |
| Planning-Based | Structured predictable workflows | Brittle to mid-task changes |
| Sequential | Stage-dependent multi-step processes | Early failures propagate |
| Parallel | Independent concurrent analyses | Higher resource consumption |
| Coordinator | Adaptive routing across specialists | Central point of failure |
| Hierarchical | Complex decomposition exceeding context windows | Highest latency and cost |
| Swarm | Creative, multi-perspective problems | Difficult to control, runaway risk |
| Loop/Critique | Iterative quality assurance | Cost grows with iteration count |
| Human-in-the-Loop | High-stakes regulated decisions | Latency from human review |

Scalability Considerations
Agent system scalability has two axes:
- Horizontal scaling — adding more specialized agents to cover more task types — requires robust state management, inter-agent authentication, and context compaction to prevent token overload.
- Vertical scaling — increasing reasoning depth per task — requires managing nested context, preventing hallucination accumulation across reasoning layers, and implementing exit conditions to avoid infinite loops.
Production data shows orchestrated multi-agent systems have 3.2x lower failure rates than unorchestrated systems. For most teams, this means choosing a formal orchestration framework — LangGraph, AutoGen, Google ADK, or CrewAI — over building custom coordination logic from scratch.
Working with an Experienced Partner
For organizations navigating these decisions across healthcare, fintech, and retail, Codewave uses its QuantumAgile™ methodology to move teams from architecture selection to validated, working agent systems in days. With experience across 15+ industries, the approach reduces the pattern-selection risk that sends many enterprise AI projects back to square one.
Frequently Asked Questions
What are the different types of AI agent patterns?
AI agent patterns fall into three categories: single-agent (ReAct, planning-based), multi-agent (sequential, parallel, coordinator, hierarchical, swarm), and iterative/special-purpose (loop, review-critique, human-in-the-loop). Each optimizes for different trade-offs in task complexity, latency, and cost.
What is the 7 layer architecture of Agentic AI?
Agentic AI architectures are commonly described through seven functional layers: infrastructure (compute/storage), model (LLMs/SLMs), memory (short-term context and long-term storage), planning (reasoning/decomposition), action (tool execution), communication (user and inter-agent interfaces), and security/governance (permissions, compliance, monitoring). The exact layer count varies by framework, but these functional categories appear consistently across implementations.
What are the 4 pillars of AI agents?
The four pillars are perception (understanding inputs), memory (retaining context), planning (decomposing goals into steps), and execution (acting through tools and systems). Every agent architecture — regardless of orchestration pattern — is built on these four functions.
When should you use a single-agent vs. multi-agent architecture?
Use a single agent for focused, single-domain tasks with fewer than 8-10 tools. Switch to multi-agent when tasks span multiple domains, require parallel processing, or need distinct security boundaries per function — accepting higher coordination overhead in exchange for specialization and scale.
What are the biggest challenges in scaling AI agent systems in production?
The main challenges are context degradation over long conversations, cascading failures in multi-agent pipelines, cost unpredictability from multiple LLM calls, and governance complexity from per-agent hardcoded policies. Mitigating these requires formal orchestration frameworks, context compaction, and centralized policy enforcement.
How do you ensure reliability and safety in multi-agent architectures?
Core safeguards include iteration caps on loop patterns, output validation before downstream handoff, inter-agent authentication, and least-privilege access enforced centrally rather than embedded per agent. The NIST AI Agent Standards Initiative (February 2026) formalizes agent identity, zero-trust principles, and tamper-proof auditing requirements.


